When you’re used to working with numbers, patterns, and statistical models, qualitative data can feel a bit slippery. How do you take hundreds of open-text survey responses, interview transcripts, or notes from workshops and turn them into something structured? That’s where inductive coding comes in.
What is inductive coding?
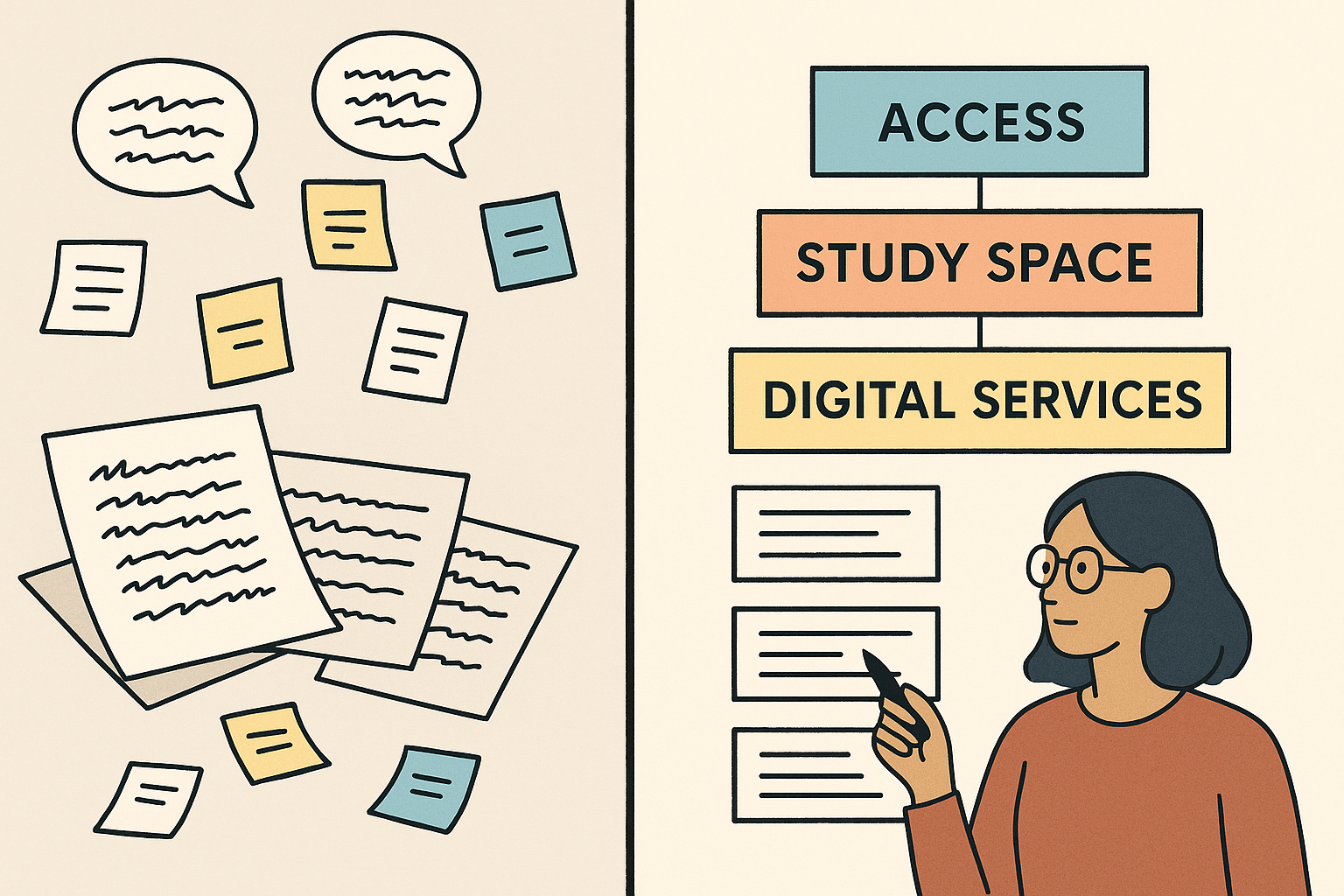
Inductive coding is a way of analysing qualitative data without starting from a fixed framework. Instead of applying pre-determined categories, you let the codes (labels or tags) emerge from the data itself.
For example:
- If you ask students “What could we improve about our library?”, you might see responses about opening hours, seating, or online resources. With inductive coding, you’d read through the responses and create codes like “access,” “study space,” or “digital services” as you notice themes appearing.
It’s the opposite of deductive coding, where you’d start with a set of categories in advance and simply apply them.
When to use it
Inductive coding is useful when:
- You’re exploring a new area and don’t want to impose assumptions.
- You don’t have an existing model, framework, or set of categories.
- You want to surface unexpected themes or insights.
- The goal is discovery rather than confirmation.
It’s especially common in early-stage research, exploratory evaluations, and user feedback analysis.
Benefits
- Flexibility: You can capture the richness of responses without being constrained by a pre-set structure.
- Discovery of new ideas: Surprising themes often emerge, which can be particularly valuable when you don’t know what to expect.
- Grounded in real voices: The categories come directly from participants’ words, not researcher assumptions.
Drawbacks
- Time consuming: Reading through and coding large datasets takes a lot of effort.
- Less consistency: Different researchers may code the same data differently unless you agree clear definitions.
- Harder to compare: Because codes are generated anew, they may not align neatly with other datasets or previous research.
- Risk of bias: Even though it’s “inductive,” researchers still make judgments about what counts as a code.
Bringing it back to numbers
For those from a quantitative background, think of inductive coding as a way to transform unstructured text into categories that you can later count, compare, or test. Once the coding is done, you might find that 40% of students mentioned seating, 30% mentioned digital resources, and so on. The difference is that the categories didn’t exist before you looked at the data – you built them from the ground up.